Calcite框架分享-stage1
目的
- 宏观上了解 Calcite 主要在做什么
- 对 Calcite 常见的概念有一定了解
- 了解我们的场景以及对 calcite 的部分定制方式
Calcite 在做什么
常见的应用场景:
- sql 解析, 获取 sql 语义相关的信息
- sql 转换, 提供统一的 sql 语义(一般不涉及关系表达式)
- sql 优化: 基于 sql 以及 metadata, 生成对应的关系表达式, 进行优化
- 之后可能会生成回 sql, 或者 spark plan, 或者物理执行
- sql 执行: 默认提供了 Enumerable/Bindable 的执行。
- Enumerable 类似解释执行, 在算子当前的上下文中执行.
- Bindable 类似编译执行, 利用 janimo 做 codegen.
其中:
- sql 解析相对而言最为标准化, 业内各种的工具。手写的 sql parser 也有很多。
- 主要难点在于标准不统一,各家的 sql 标准实现程度大同小异,自定义语法结构较多。
- sql 转换, 基于 sql 语义层的转换相对比较固定。
- 有点类似于解析这部分, 难点在于特性会比较多。
- 比如不同方言里的同名 udf 语义不一样,需要适配。
- 有点类似于解析这部分, 难点在于特性会比较多。
- 基于关系表达式与元信息进行优化, 这部分的开源框架较少,算是 calcite 最核心的能力之一。
- 不同的物理特征,执行引擎下,优化规则的差异会比较大
- 从而 calcite 更多在于, 提供统一的框架(planner)进行优化, 而优化规则更多的交给使用方去自定义。
- 同时提供了很多默认优化规则
- TODO: 补充几个具体的案例
简而言之: Apache Calcite is a foundational software framework that provides query processing , optimization , and query language support to many popular open-source data processing systems.
几个关键词:
- query language support
- optimization
- query processing
- framework
Calcite 怎么做的
sql 解析
基本功能
利用 javacc 实现。
举个例子:
select 1 from dual;
在 sql 的语义层面,可以表示为:
(SqlSelect ;; select (SqlInt 1) ;; 1 (SqlIdentifier "dual") ;; from dual nil ;; there is no where )
再举个例子:
select a from b where c != 1 order by d desc limit 10;
可以表示为:
(SqlOrderBy ;; order by (SqlDesc (SqlIdentifier "d")) ;; d desc (SqlLimit (SqlInt 10)) ;; limit 10 (SqlSelect ;; select (SqlIdentifier "a") ;; a (SqlIdentifier "b") ;; from b (SqlPredicate (!= (SqlIdentifer "c") (SqlInt 1))) ;; where c != 1 ) )
为了做到这个效果, 语法文件可以定义大致如下:
SqlOrderBy: SqlSelect() [<ORDER> <BY> SqlIdentifer() [<ASC>|<DESC>] [ <LIMIT> SqlInt()] SqlSelect: <SELECT> [SqlIdentifer()]+ <FROM> SqlIdentifer() <WHERE> SqlCall() SqlCall: (SqlIdentifer() | SqlConstant()) SqlOperator() (SqlIdentifer() | SqlConstant()) // only support infix expression SqlIdentifer: token() SqlInt: [0~9]+ token: [a~z|A~Z]+ [0~9|a~z|A~Z]*
以上代码仅供参考, 具体还是得看 javacc...
多方言的支持
- 利用
freemarker支持(生成新的parser.jj文件)- 扩展新的语法元素.
- 调整 reserved word, 增加 keyword, 等等
- 针对多方言抽象出一套常见的配置
- 如何区分字符常量与标识符。比如 "`", "'", "\"" 在不同的方言中,分别可以表示字符常量。
- 是否支持中缀表达式
- 是否支持复合标识符, 比如
a.b - 等等
- 如果需要更定制的版本, 支持自行通过
parser.jj文件修改,生成新的 parser 实现。
sql 生成
本质上是 unparse 的过程。在解析完成后, Calcite 会生成 SqlNode, 如上述例子所展示, 本质上就是一颗树.
从而只需要遍历这个树, 基于每个节点自身的规则, 以及对应的方言需要, 生成对应的片段即可。
以 SqlSelectOperator 的 sql 生成(删除了一些代码)为例
@Override public void unparse(
SqlWriter writer,
SqlCall call,
int leftPrec,
int rightPrec) {
SqlSelect select = (SqlSelect) call;
final SqlWriter.Frame selectFrame =
writer.startList(SqlWriter.FrameTypeEnum.SELECT);
writer.sep("SELECT");
final SqlNodeList selectClause = select.selectList;
writer.list(SqlWriter.FrameTypeEnum.SELECT_LIST, SqlWriter.COMMA,
selectClause);
if (select.from != null) {
// Calcite SQL requires FROM but MySQL does not.
writer.sep("FROM");
// for FROM clause, use precedence just below join operator to make
// sure that an un-joined nested select will be properly
// parenthesized
final SqlWriter.Frame fromFrame =
writer.startList(SqlWriter.FrameTypeEnum.FROM_LIST);
select.from.unparse(
writer,
SqlJoin.OPERATOR.getLeftPrec() - 1,
SqlJoin.OPERATOR.getRightPrec() - 1);
writer.endList(fromFrame);
}
SqlNode where = select.where;
if (where != null) {
writer.sep("WHERE");
if (!writer.isAlwaysUseParentheses()) {
SqlNode node = where;
// decide whether to split on ORs or ANDs
SqlBinaryOperator whereSep = SqlStdOperatorTable.AND;
if ((node instanceof SqlCall)
&& node.getKind() == SqlKind.OR) {
whereSep = SqlStdOperatorTable.OR;
}
// unroll whereClause
final List<SqlNode> list = new ArrayList<>(0);
while (node.getKind() == whereSep.kind) {
assert node instanceof SqlCall;
final SqlCall call1 = (SqlCall) node;
list.add(0, call1.operand(1));
node = call1.operand(0);
}
list.add(0, node);
// unparse in a WHERE_LIST frame
writer.list(SqlWriter.FrameTypeEnum.WHERE_LIST, whereSep,
new SqlNodeList(list, where.getParserPosition()));
} else {
where.unparse(writer, 0, 0);
}
}
writer.endList(selectFrame);
}
sql -> rel (转换为关系表达式)
和 unparse 的过程非常类似。同样看一段 SqlSelect -> RelNode 的过程
/**
* Implementation of {@link #convertSelect(SqlSelect, boolean)};
* derived class may override.
*/
protected void convertSelectImpl(
final Blackboard bb,
SqlSelect select) {
convertFrom(
bb,
select.getFrom());
convertWhere(
bb,
select.getWhere());
final List<SqlNode> orderExprList = new ArrayList<>();
final List<RelFieldCollation> collationList = new ArrayList<>();
gatherOrderExprs(
bb,
select,
select.getOrderList(),
orderExprList,
collationList);
final RelCollation collation =
cluster.traitSet().canonize(RelCollations.of(collationList));
convertOrder(
select, bb, collation, orderExprList, select.getOffset(),
select.getFetch());
bb.setRoot(bb.root(), true);
}
protected void convertFrom(
Blackboard bb,
@Nullable SqlNode from,
@Nullable List<String> fieldNames) {
switch (from.getKind()) {
case TABLE_REF:
call = (SqlCall) from;
convertIdentifier(bb, call.operand(0), null, call.operand(1));
return;
}
}
private void convertIdentifier(Blackboard bb, SqlIdentifier id,
@Nullable SqlNodeList extendedColumns, @Nullable SqlNodeList tableHints) {
final String datasetName =
datasetStack.isEmpty() ? null : datasetStack.peek();
final boolean[] usedDataset = {false};
RelOptTable table =
SqlValidatorUtil.getRelOptTable(fromNamespace, catalogReader,
datasetName, usedDataset);
assert table != null : "getRelOptTable returned null for " + fromNamespace;
final RelNode tableRel;
// Review Danny 2020-01-13: hacky to construct a new table scan
// in order to apply the hint strategies.
final List<RelHint> hints = hintStrategies.apply(
SqlUtil.getRelHint(hintStrategies, tableHints),
LogicalTableScan.create(cluster, table, ImmutableList.of()));
tableRel = toRel(table, hints);
bb.setRoot(tableRel, true);
if (usedDataset[0]) {
bb.setDataset(datasetName);
}
}
/**
* Converts a WHERE clause.
*
* @param bb Blackboard
* @param where WHERE clause, may be null
*/
private void convertWhere(
final Blackboard bb,
final @Nullable SqlNode where) {
if (where == null) {
return;
}
SqlNode newWhere = pushDownNotForIn(bb.scope(), where);
replaceSubQueries(bb, newWhere, RelOptUtil.Logic.UNKNOWN_AS_FALSE);
final RexNode convertedWhere = bb.convertExpression(newWhere);
final RexNode convertedWhere2 =
RexUtil.removeNullabilityCast(typeFactory, convertedWhere);
// only allocate filter if the condition is not TRUE
if (convertedWhere2.isAlwaysTrue()) {
return;
}
final RelFactories.FilterFactory filterFactory =
RelFactories.DEFAULT_FILTER_FACTORY;
final RelNode filter =
filterFactory.createFilter(bb.root(), convertedWhere2, ImmutableSet.of());
final RelNode r = filter;
bb.setRoot(r, false);
}
rel -> rel (optimize)
这一部分为 calcite 中最为核心的逻辑,共可以分成以下几部分探讨:
- 如何将一个关系表达式生成为另一个等价的关系表达式
- 如何尽可能完备的生成所有的等价表达式
- 一个关系表达式为一颗树,其中任一子树,均可能生成等价的表达式
- 生成后,可能存在新的子树,也可以生成新的等价表达式
- 如何选择最优的表达式
这三个问题在另一个部分中详述。
rel -> sql
具体代码和 unparse, sql -> rel 等,结构上如出一辙。可参考: RelToSqlConverter 中的 visit(Project e), visit(Aggregate e) 等等。
同样看一个例子,有些直观的效果上的理解
sql
select idc, domain FROM metricsdb.domain_idc_quality
sqlNode
(SqlSelect (SqlSelectList (SqlIdentifier "idc") (SqlIdentifier "domain")) (SqlFrom (SqlIdentifier (SqlNames "metricsdb" "domain_idc_quality"))))relNode
(LogicalProject (exprs $3 $4) (LogicalTableScan (table "metricsdb.domain_idc_quality")))
优化器详细分析
等价表达式生成 (Rule)
这部分的逻辑是: 先粗粒度匹配, 匹配上了之后执行具体的 onMatch() .
在 onMatch 中,进行各种校验,生成的逻辑,生成等价表达式之后,调用 transformTo 将等价表达式给 planner, 进行后续的逻辑。
常见的粗粒度匹配为: 支持什么 Operand (亦即 RelNode), 仅从类型和树的结构进行描述。比如
AggregateJoinTransposeRule, 需要这颗子树(亦即当前的 RelNode)的顶点是Aggregate, 这个Aggregate有一个Input, 且Input是Join/** * Extended instance that can push down aggregate functions. */ Config EXTENDED = EMPTY.as(Config.class) .withOperandFor(LogicalAggregate.class, LogicalJoin.class, true); /** * Defines an operand tree for the given classes, and also sets * {@link #isAllowFunctions()}. */ default Config withOperandFor(Class<? extends Aggregate> aggregateClass, Class<? extends Join> joinClass, boolean allowFunctions) { return withAllowFunctions(allowFunctions) .withOperandSupplier(b0 -> b0.operand(aggregateClass) .predicate(agg -> isAggregateSupported(agg, allowFunctions)) .oneInput(b1 -> b1.operand(joinClass).anyInputs())) .as(Config.class); }FilterProjectTransposeRule, 需要顶点是Filter且condition中不含有CorrelationVariable1, 只有一个Input是ProjectConfig DEFAULT = EMPTY.as(Config.class) .withOperandFor(Filter.class, f -> !RexUtil.containsCorrelation(f.getCondition()), Project.class, p -> true) .withCopyFilter(true) .withCopyProject(true); /** Defines an operand tree for the given 2 classes. */ default Config withOperandFor(Class<? extends Filter> filterClass, Predicate<Filter> filterPredicate, Class<? extends Project> projectClass, Predicate<Project> projectPredicate) { return withOperandSupplier(b0 -> b0.operand(filterClass).predicate(filterPredicate).oneInput(b1 -> b1.operand(projectClass).predicate(projectPredicate).anyInputs())) .as(Config.class); }
具体的等价表达式的生成逻辑就各有不同了。举两个例子
案例 1: ProjectMergeRule
- 如果这颗子树是
Project(top) <- Project(bottom)这种形状, 则进入onMatch - 将 top 的表达式列表中对 bottom 的引用,替换为对 bottom 的 input 的引用,生成新的表达式列表
- 使用新的表达式列表与 bottom 的 input, 生成新的
Project。 从而两层 project 转换成了 一层。
@Override public boolean matches(RelOptRuleCall call) {
final Project topProject = call.rel(0);
final Project bottomProject = call.rel(1);
return topProject.getConvention() == bottomProject.getConvention();
}
@Override public void onMatch(RelOptRuleCall call) {
final Project topProject = call.rel(0);
final Project bottomProject = call.rel(1);
final RelBuilder relBuilder = call.builder();
final List<RexNode> newProjects =
RelOptUtil.pushPastProjectUnlessBloat(topProject.getProjects(),
bottomProject, config.bloat());
if (newProjects == null) {
// Merged projects are significantly more complex. Do not merge.
return;
}
final RelNode input = bottomProject.getInput();
if (RexUtil.isIdentity(newProjects, input.getRowType())) {
if (config.force()
|| input.getRowType().getFieldNames()
.equals(topProject.getRowType().getFieldNames())) {
call.transformTo(input);
return;
}
}
// replace the two projects with a combined projection
relBuilder.push(bottomProject.getInput());
relBuilder.project(newProjects, topProject.getRowType().getFieldNames());
call.transformTo(relBuilder.build());
}
案例 2: FilterAggregateTransposeRule
这个规则将 filter 下推到 aggregate 之前。
- 如果这颗子树是
Filter <- Aggregate这种形状,则进入onMatch - 如果
condition中的column reference均在Aggregate的GroupSet中, 则修改引用,生成新的Filter, 下推给Aggregate作为新的Input - 将剩余
condition生成新的Filter, 以Aggregate为Input
Config DEFAULT = EMPTY.as(Config.class)
.withOperandFor(Filter.class, Aggregate.class);
/** Defines an operand tree for the given 2 classes. */
default Config withOperandFor(Class<? extends Filter> filterClass,
Class<? extends Aggregate> aggregateClass) {
return withOperandSupplier(b0 ->
b0.operand(filterClass).oneInput(b1 ->
b1.operand(aggregateClass).anyInputs()))
.as(Config.class);
}
@Override public void onMatch(RelOptRuleCall call) {
final Filter filterRel = call.rel(0);
final Aggregate aggRel = call.rel(1);
final List<RexNode> conditions =
RelOptUtil.conjunctions(filterRel.getCondition());
final List<RexNode> pushedConditions = new ArrayList<>();
final List<RexNode> remainingConditions = new ArrayList<>();
for (RexNode condition : conditions) {
ImmutableBitSet rCols = RelOptUtil.InputFinder.bits(condition);
if (canPush(aggRel, rCols)) {
pushedConditions.add(
condition.accept(
new RelOptUtil.RexInputConverter(rexBuilder, origFields,
aggRel.getInput(0).getRowType().getFieldList(),
adjustments)));
} else {
remainingConditions.add(condition);
}
}
final RelBuilder builder = call.builder();
RelNode rel =
builder.push(aggRel.getInput()).filter(pushedConditions).build();
if (rel == aggRel.getInput(0)) {
return;
}
rel = aggRel.copy(aggRel.getTraitSet(), ImmutableList.of(rel));
rel = builder.push(rel).filter(remainingConditions).build();
call.transformTo(rel);
}
private static boolean canPush(Aggregate aggregate, ImmutableBitSet rCols) {
// If the filter references columns not in the group key, we cannot push
final ImmutableBitSet groupKeys =
ImmutableBitSet.range(0, aggregate.getGroupSet().cardinality());
if (!groupKeys.contains(rCols)) {
return false;
}
if (aggregate.getGroupType() != Group.SIMPLE) {
// If grouping sets are used, the filter can be pushed if
// the columns referenced in the predicate are present in
// all the grouping sets.
for (ImmutableBitSet groupingSet : aggregate.getGroupSets()) {
if (!groupingSet.contains(rCols)) {
return false;
}
}
}
return true;
}
等价图生成
先看一个例子:
树
LogicalAggregate(group=[{0, 1, 2, 3, 4}], NASA2usage=[SUM($5)], NASA2videousage=[SUM($6)], NASA2audiousage=[SUM($7)], alltotalusage=[SUM($8)], allaudioUsage=[SUM($9)], allvideoUsage=[SUM($10)]) LogicalProject(date=[$0], vid=[$1], projectName=[$14], companyid=[$15], companyname=[$16], totalusage=[$5], videousage=[$6], audio_usage=[$7], audio_video=[$10], audio=[$11], video=[$12]) LogicalJoin(condition=[=($1, $13)], joinType=[left]) LogicalJoin(condition=[AND(=($1, $9), =($0, $8))], joinType=[left]) LogicalAggregate(group=[{0, 1, 2, 3, 4}], totalusage=[SUM($5)], videousage=[SUM($6)], audio_usage=[SUM($7)]) LogicalProject(date=[$0], vid=[$5], domain=[$8], os=[$11], ver=[$12], audio_video=[$20], video=[$26], audio=[$23]) LogicalFilter(condition=[AND(=($1, '(product_line,product_type,vid,domain,os,ver)'), OR(=($12, '3.0.0.11'), =($12, '3,0,0,16'), =($12, '3.0.0.17'), =($12, '3.0.0.19'), =($12, '3.0.0.18'), =($12, '3.0.20.20'), =($12, '3.0.20.21')), >=($0, '2020-08-01'))]) LogicalTableScan(table=[[metricsdb, agora_vid_usage_cube_di]]) LogicalAggregate(group=[{0, 1}], audio_video=[SUM($2)], audio=[SUM($3)], video=[SUM($4)]) LogicalProject(date=[$0], vid=[$5], audio_video=[$20], audio=[$23], video=[$26]) LogicalFilter(condition=[AND(>=($0, '2020-08-01'), =($1, '(product_line,product_type,vid,domain,os,ver)'))]) LogicalTableScan(table=[[metricsdb, agora_vid_usage_cube_di]]) LogicalProject(vid=[$0], projectName=[$1], companyid=[$2], companyname=[$3]) LogicalTableScan(table=[[metricsdb, new_vendor_dimension]])图
Breadth-first from root: { rel#57:HepRelVertex(rel#56:LogicalAggregate.(input=HepRelVertex#55,group={0, 1, 2, 3, 4},NASA2usage=SUM($5),NASA2videousage=SUM($6),NASA2audiousage=SUM($7),alltotalusage=SUM($8),allaudioUsage=SUM($9),allvideoUsage=SUM($10))) = rel#56:LogicalAggregate.(input=HepRelVertex#55,group={0, 1, 2, 3, 4},NASA2usage=SUM($5),NASA2videousage=SUM($6),NASA2audiousage=SUM($7),alltotalusage=SUM($8),allaudioUsage=SUM($9),allvideoUsage=SUM($10)), rowcount=1.585, cumulative cost=457.1676257395745 rel#55:HepRelVertex(rel#54:LogicalProject.(input=HepRelVertex#53,inputs=0..1,exprs=[$14, $15, $16, $5, $6, $7, $10, $11, $12])) = rel#54:LogicalProject.(input=HepRelVertex#53,inputs=0..1,exprs=[$14, $15, $16, $5, $6, $7, $10, $11, $12]), rowcount=15.85, cumulative cost=454.27500028610234 rel#53:HepRelVertex(rel#52:LogicalJoin.(left=HepRelVertex#48,right=HepRelVertex#51,condition==($1, $13),joinType=left)) = rel#52:LogicalJoin.(left=HepRelVertex#48,right=HepRelVertex#51,condition==($1, $13),joinType=left), rowcount=15.85, cumulative cost=438.4250002861023 rel#48:HepRelVertex(rel#47:LogicalJoin.(left=HepRelVertex#40,right=HepRelVertex#46,condition=AND(=($1, $9), =($0, $8)),joinType=left)) = rel#47:LogicalJoin.(left=HepRelVertex#40,right=HepRelVertex#46,condition=AND(=($1, $9), =($0, $8)),joinType=left), rowcount=1.0, cumulative cost=222.5750002861023 rel#51:HepRelVertex(rel#50:LogicalProject.(input=HepRelVertex#49,inputs=0..3)) = rel#50:LogicalProject.(input=HepRelVertex#49,inputs=0..3), rowcount=100.0, cumulative cost=200.0 rel#40:HepRelVertex(rel#39:LogicalAggregate.(input=HepRelVertex#38,group={0, 1, 2, 3, 4},totalusage=SUM($5),videousage=SUM($6),audio_usage=SUM($7))) = rel#39:LogicalAggregate.(input=HepRelVertex#38,group={0, 1, 2, 3, 4},totalusage=SUM($5),videousage=SUM($6),audio_usage=SUM($7)), rowcount=1.0, cumulative cost=105.16250014305115 rel#46:HepRelVertex(rel#45:LogicalAggregate.(input=HepRelVertex#44,group={0, 1},audio_video=SUM($2),audio=SUM($3),video=SUM($4))) = rel#45:LogicalAggregate.(input=HepRelVertex#44,group={0, 1},audio_video=SUM($2),audio=SUM($3),video=SUM($4)), rowcount=1.0, cumulative cost=116.41250014305115 rel#49:HepRelVertex(rel#28:LogicalTableScan.(table=[metricsdb, new_vendor_dimension])) = rel#28:LogicalTableScan.(table=[metricsdb, new_vendor_dimension]), rowcount=100.0, cumulative cost=100.0 rel#38:HepRelVertex(rel#37:LogicalProject.(input=HepRelVertex#36,inputs=0,exprs=[$5, $8, $11, $12, $20, $26, $23])) = rel#37:LogicalProject.(input=HepRelVertex#36,inputs=0,exprs=[$5, $8, $11, $12, $20, $26, $23]), rowcount=1.875, cumulative cost=103.75 rel#44:HepRelVertex(rel#43:LogicalProject.(input=HepRelVertex#42,inputs=0,exprs=[$5, $20, $23, $26])) = rel#43:LogicalProject.(input=HepRelVertex#42,inputs=0,exprs=[$5, $20, $23, $26]), rowcount=7.5, cumulative cost=115.0 rel#36:HepRelVertex(rel#35:LogicalFilter.(input=HepRelVertex#34,condition=AND(=($1, '(product_line,product_type,vid,domain,os,ver)'), OR(=($12, '3.0.0.11'), =($12, '3,0,0,16'), =($12, '3.0.0.17'), =($12, '3.0.0.19'), =($12, '3.0.0.18'), =($12, '3.0.20.20'), =($12, '3.0.20.21')), >=($0, '2020-08-01')))) = rel#35:LogicalFilter.(input=HepRelVertex#34,condition=AND(=($1, '(product_line,product_type,vid,domain,os,ver)'), OR(=($12, '3.0.0.11'), =($12, '3,0,0,16'), =($12, '3.0.0.17'), =($12, '3.0.0.19'), =($12, '3.0.0.18'), =($12, '3.0.20.20'), =($12, '3.0.20.21')), >=($0, '2020-08-01'))), rowcount=1.875, cumulative cost=101.875 rel#42:HepRelVertex(rel#41:LogicalFilter.(input=HepRelVertex#34,condition=AND(>=($0, '2020-08-01'), =($1, '(product_line,product_type,vid,domain,os,ver)')))) = rel#41:LogicalFilter.(input=HepRelVertex#34,condition=AND(>=($0, '2020-08-01'), =($1, '(product_line,product_type,vid,domain,os,ver)'))), rowcount=7.5, cumulative cost=107.5 rel#34:HepRelVertex(rel#16:LogicalTableScan.(table=[metricsdb, agora_vid_usage_cube_di])) = rel#16:LogicalTableScan.(table=[metricsdb, agora_vid_usage_cube_di]), rowcount=100.0, cumulative cost=100.0 }
优化的基础就是: 将树生成图,而后基于某种遍历方式,将每个顶点(代表一颗子树)都尝试生成对应的等价表达式, 并加入图中。 2 最终基于图中的信息,获得最终的执行计划。
Planner
在 calcite 中, planner 负责规则的协调/迭代, 树的等价生成,树的选择等。
默认实现中, 共提供了两种 planner, 分别为 HepPlanner 与 VolcanoPlanner.
常规意义上,一般认为 HepPlanner 是 Rule Based, 而 VolcanoPlanner 是 Cost Based.
- Hep 会在图中进行替换,使用新表达式替换已有,而后基于新图,继续生成,直至图不变为止。
- Volcanno 会保留所有的等价集合, 最终选择一个 cost 最低的方案。
Hep Planner
- Hep 的生成规则相对简单, 遍历所有节点, 与所有规则
- 规则匹配完成后, 生成新表达式则加入图中, 并移除旧表达式, 重新执行 1
- 如果生成多个新表达式, 则基于 cost, 取一个局部最优
- 移除旧表达式的过程是指: 将所有以旧表达式为输入的节点, 其引用调整为新表达式
- 当所有节点遍历后, 不会生成新表达式, 则结束
- 最终由根节点遍历,即可获取最终生成的 Plan
note:
- Hep 并不保证可以生成全部的等价表达式,且最终结果与规则执行顺序也有很大的关系。
- 提供了多种 Iterator 用于遍历图
- 对于重复生成造成的循环, 比如 A -> B, B -> A 这种, 会在加入图时做过滤
Volcano Planner
- 任何关系表达式,会将其所有节点进行规则匹配,将匹配完成的规则放入待执行队列.
- 匹配逻辑为: 规则描述树的结构(每一层的节点类型), 基于节点类型,找到相关的规则。基于当前类型在规则中的位置,进行匹配。
- 比如: 一个规则
Project <- Aggregate- 匹配
Aggregate节点时, 找到该规则,找其上级节点是否为Project - 匹配
Project节点时, 找到该规则,找其下级节点是否为Aggregate
- 匹配
- 遍历匹配的规则清单,执行,完成后,如果生成新的表达式,同 1
- 规则清单为空时,则完成生成,退出。3
生成完成后,是一张图。其中每个节点为一个集合,集合内是等价表达式。 表达式间会有依赖(比如 Aggregate 作为 Project 的 input )。
图中存在多条路径可以达到 root 节点(目标的关系表达式), 最终就会需要从这张图中找到一个开销最低的路径.(亦即下图中由顶点开始的蓝线部分)
同样看一下例子:
- sql
SELECT
date,
vid,
domain,
os,
ver,
sum(audio_video) AS totalusage,
sum(video) AS videousage,
sum(audio) AS audio_usage
FROM
metricsdb.agora_vid_usage_cube_di
WHERE
group_mark = '(product_line,product_type,vid,domain,os,ver)'
AND ver IN (
'3.0.0.11',
'3,0,0,16',
'3.0.0.17',
'3.0.0.19',
'3.0.0.18',
'3.0.20.20',
'3.0.20.21'
)
AND date >= '2020-08-01'
GROUP BY
1,
2,
3,
4,
5
- 关系表达式
LogicalAggregate(subset=[rel#27:RelSubset#3.ENUMERABLE.[]], group=[{0, 1, 2, 3, 4}], totalusage=[SUM($5)], videousage=[SUM($6)], audio_usage=[SUM($7)]): rowcount = 1.0, cumulative cost = {1.4125001430511475 rows, 0.0 cpu, 0.0 io}, id = 25
LogicalProject(subset=[rel#24:RelSubset#2.NONE.[]], date=[$0], vid=[$2], domain=[$3], os=[$4], ver=[$5], audio_video=[$6], video=[$8], audio=[$7]): rowcount = 1.0, cumulative cost = {1.0 rows, 8.0 cpu, 0.0 io}, id = 23
LogicalFilter(subset=[rel#22:RelSubset#1.NONE.[]], condition=[AND(=($1, '(product_line,product_type,vid,domain,os,ver)'), OR(=($5, '3.0.0.11'), =($5, '3,0,0,16'), =($5, '3.0.0.17'), =($5, '3.0.0.19'), =($5, '3.0.0.18'), =($5, '3.0.20.20'), =($5, '3.0.20.21')), >=($0, '2020-08-01'))]): rowcount = 1.0, cumulative cost = {1.0 rows, 1.0 cpu, 0.0 io}, id = 21
LogicalTableScan(subset=[rel#20:RelSubset#0.NONE.[]], table=[[metricsdb, agora_vid_usage_cube_di]]): rowcount = 1.0, cumulative cost = {1.0 rows, 2.0 cpu, 0.0 io}, id = 16
- 初始图
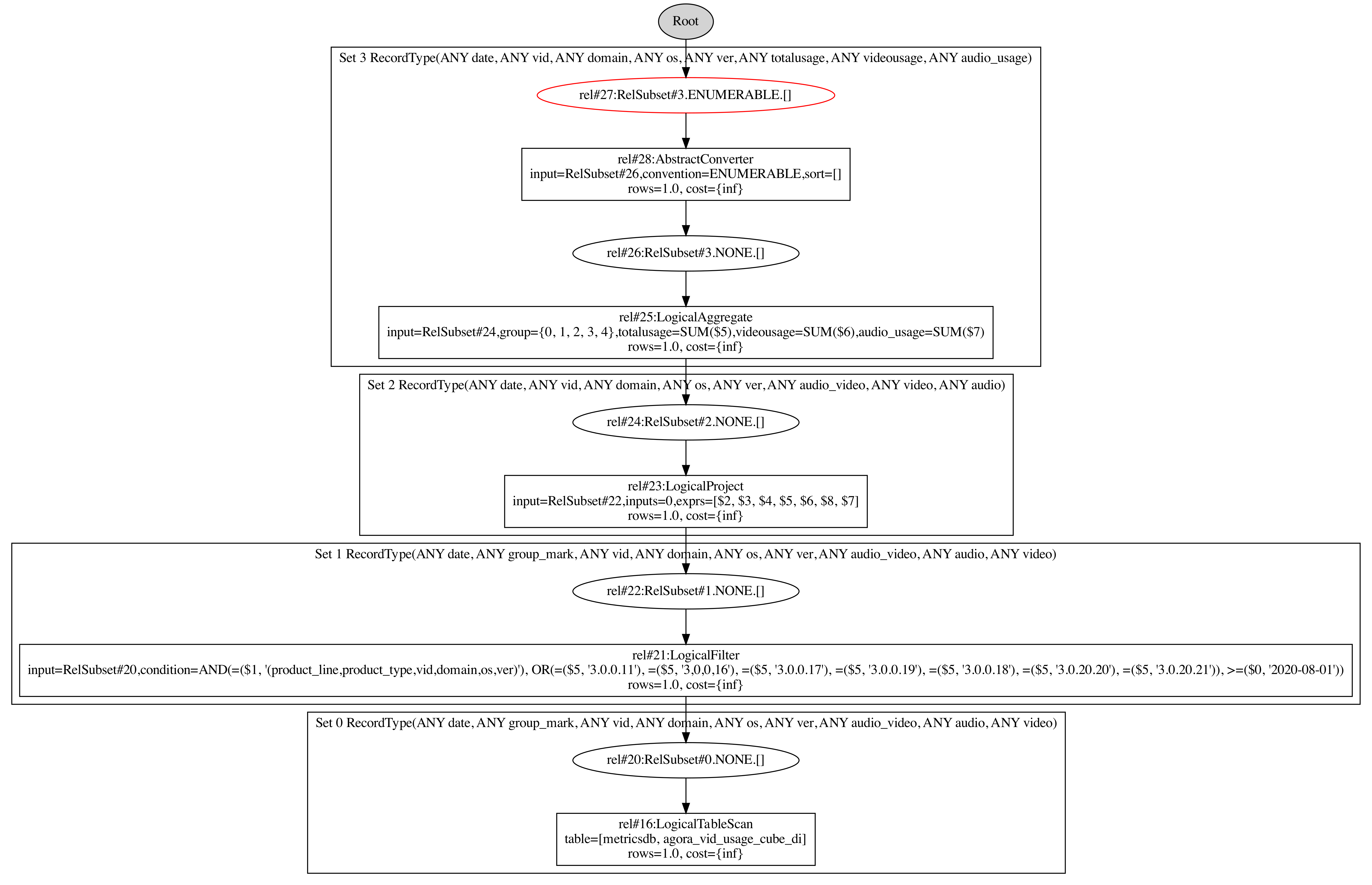
- 完成图
部分应用场景
遍历 RelNode 获取 TableRef
遍历 SqlNode 查询相关的 TableRef
/**
* find all databases from sql node.
*
* @param sqlNode sql node
* @return databases
*/
public static List<String> findDatabases(SqlNode sqlNode) {
if (sqlNode == null) {
return null;
}
Set<String> databases = new HashSet<>();
sqlNode.accept(
new SqlBasicVisitor<Void>() {
public Void visit(SqlCall call) {
if (call instanceof SqlSelect) {
SqlNode from = ((SqlSelect) call).getFrom();
return from == null ? null : from.accept(this);
} else {
return super.visit(call);
}
}
public Void visit(SqlIdentifier id) {
if (id.names.size() != 2) {
return null;
}
id.names.stream().findFirst().ifPresent(databases::add);
return super.visit(id);
}
});
return databases.isEmpty() ? null : new ArrayList<>(databases);
}
解决 quote 的中文乱码(输出时 unicode 编码)问题
public void quoteStringLiteral(StringBuilder buf, @Nullable String charsetName,
String val) {
if (containsNonAscii(val) && charsetName == null) {
buf.append(literalQuoteString);
buf.append(val.replace(literalEndQuoteString, literalEscapedQuote));
buf.append(literalEndQuoteString);
return;
}
return super.quoteStringLiteral(buf, charsetName, val);
//if (containsNonAscii(val) && charsetName == null) {
// quoteStringLiteralUnicode(buf, val);
//} else {
// if (charsetName != null) {
// buf.append("_");
// buf.append(charsetName);
// }
// buf.append(literalQuoteString);
// buf.append(val.replace(literalEndQuoteString, literalEscapedQuote));
// buf.append(literalEndQuoteString);
//}
}